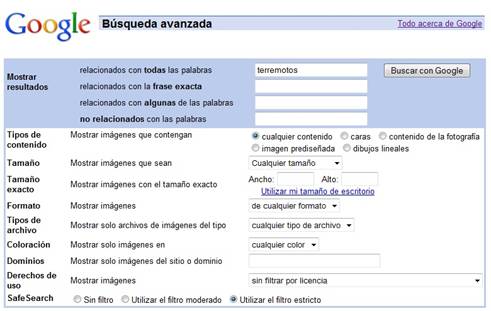
Web Superficial y la Web Profunda.
Para buscar bien, es imprescindible tener en cuenta, que además de los buscadores
convencionales, hay disponibles otras fuentes específicas de información.
Los buscadores tradicionales sólo ofrecen acceso a una pequeña parte de lo que existe online, lo
que se ha comenzado a llamar la Web superficial o visible. Lo que resta, la Web profunda o
invisible, es un amplio banco de información ubicado en catálogos, revistas digitales, blogs,
entradas a diccionarios y contenido de sitios que demandan un login (aunque sea gratuito) y otros
tipos de contenido que no aparecen entre los resultados de una búsqueda convencional.
 La Web Superficial o visible.
La Web Superficial o visible.
La Web Superficial comprende todos aquellos sitios cuya información puede ser indexada por los
robots de los buscadores convencionales y recuperada casi en su totalidad mediante una consulta
en sus formularios de búsqueda.
Las características principales de los sitios de la Web visible son: su información no está contenida en bases de datos es de libre acceso no se requiere la realización de un proceso de registro para acceder a la información. Mayoritariamente está formada por páginas Web estáticas, es decir páginas o archivos
con una URL fija y accesibles desde otro enlace.
La Web Profunda o invisible.
Web invisible es el término utilizado para describir toda la información disponible en Internet que
no se recupera interrogando a los buscadores convencionales. Generalmente es información
almacenada y accesible mediante bases de datos.
Parte de la información es "invisible" a los robots de los buscadores convencionales, ya que los
resultados se generan en la contestación a una pregunta directa mediante páginas dinámicas (ASP,
PHP, etc.) es decir páginas que no tienen una URL fija y que se construyen en el mismo instante
(temporales) desapareciendo una vez cerrada la consulta.
Sherman y Price identifican cuatro tipos de contenidos invisibles en la Web: la Web opaca (the
opaque Web), la Web privada (the private Web), la Web propietaria (the proprietary Web) y la
Web realmente invisible (the truly invisible Web).
 La Web opaca.
La Web opaca.
Está compuesta por archivos que, si bien podrían estar incluidos en los
índices de los buscadores, no lo están por alguno de los siguientes motivos:
Extensión de la indización: a veces, por economía, no todas las páginas de un sitio son
indizadas en los buscadores.
Frecuencia de la indización: los buscadores no poseen la capacidad de indizar todas las
páginas existentes; a diario se agregan y modifican muchas y la indización no se realiza
al ritmo que permita incluirlas a todas.
Número máximo de resultados visibles: aunque los motores de búsqueda arrojan a
veces un gran número de resultados, generalmente limitan el número de documentos
que se muestran (entre 200 y 1000).
URL desconectadas: las generaciones más recientes de buscadores, presentan los
documentos por relevancia basada en el número de veces que aparecen referenciados
en otros. Si un documento no tiene un link a él, desde otro documento, será imposible
que la página sea encontrada, pues no se encuentra indizada.
La Web privada.
Consiste en las páginas Web que podrían estar indizadas en los buscadores pero son excluidas deliberadamente por alguno de estos motivos:
Las páginas están protegidas por contraseñas.
Contienen un archivo “robots.txt” para evitar ser indizadas.
Contienen un campo “noindex” para evitar que el buscador pueda indizar la parte
correspondiente al cuerpo de la página.
Este segmento de la Web contiene, en general, documentos excluidos deliberadamente
por su falta de utilidad. Ya que son los dueños de la información que contienen, los que
deciden que no se encuentre disponible, por lo que difícilmente se podrán encontrar
mecanismos legítimos para franquear esa barrera.
La Web propietaria.
Incluye aquellas páginas en las que es necesario registrarse para tener
acceso al contenido, ya sea de forma gratuita o arancelada.
La Web realmente invisible.
Se compone de páginas que no pueden ser indizadas por
limitaciones técnicas de los buscadores, programas ejecutables y archivos comprimidos,
páginas generadas dinámicamente, es decir, que se generan a partir de datos que
introduce el usuario, información almacenada en bases de datos relacionales, que no
puede ser extraída a menos que se realice una petición específica.
Recursos de búsqueda en la Web Profunda.
The WWW Virtual Library se considera el catálogo más antiguo en la web y fue iniciado
por Tim Berners-Lee, el creador de la web.
Infoplease es una Web de consulta con más de 57.000 artículos de la prestigiosa
enciclopedia Columbia. Facilita la consulta de información con opciones de búsqueda por
términos o por áreas de conocimiento. Es posible acceder a un buen número de
enciclopedias, atlas, y biografías. Y también tiene algunas ramificaciones interesantes
como Factmonster.com para los niños y Biosearch, un motor de búsqueda sólo para
biografías, o información de todo lo acontecido históricamente en un determinado día.
DeepWebTech ofrece cinco motores de búsqueda para temas específicos. Los motores de
búsqueda abarcan la ciencia, medicina y negocios. El uso de estos motores de búsqueda
específicos del tema, puede consultar las bases de datos subyacentes en la Web profunda.
TechXtra centra su información, en ingeniería, matemáticas e informática. Es posible
navegar a través de una extensa lista de revistas gratuitas especializadas de ingeniería,
documentos técnicos, descargas y podcasts.











 Para comprender mejor qué es un «content curator», mejor acudir a lo que dice Dolors Reig, experta en social media, en su blog «El Caparazón»: «De forma más genérica podríamos decir que un «content curator» es un intermediario crítico del conocimiento, es alguien que busca, agrupa y comparte de forma continua lo más relevante (separa el grano de la paja) en su ámbito de especialización. A diferencia de otras profesiones (creador, por ejemplo), su objetivo fundamental es mantener la relevancia de la información que fluye libre o apoyada en herramientas concretas para la creación de entornos informacionales. Como valor competitivo, el de mantener, en última instancia, «a la última» a la empresa/organización que le forme o contrate, en cuanto al conocimiento que ahora es vital para su supervivencia».
Para comprender mejor qué es un «content curator», mejor acudir a lo que dice Dolors Reig, experta en social media, en su blog «El Caparazón»: «De forma más genérica podríamos decir que un «content curator» es un intermediario crítico del conocimiento, es alguien que busca, agrupa y comparte de forma continua lo más relevante (separa el grano de la paja) en su ámbito de especialización. A diferencia de otras profesiones (creador, por ejemplo), su objetivo fundamental es mantener la relevancia de la información que fluye libre o apoyada en herramientas concretas para la creación de entornos informacionales. Como valor competitivo, el de mantener, en última instancia, «a la última» a la empresa/organización que le forme o contrate, en cuanto al conocimiento que ahora es vital para su supervivencia».